PyCaret:机器学习模型开发变得简单

在当今快节奏的数字世界中,机构们使用低代码/无代码(LC/NC)应用来快速构建新的信息系统。本文将介绍 PyCaret,这是一个用 Python 编写的低代码机器学习库。

PyCaret 是 R 编程语言中 Caret( 分类和回归训练 Classification And REgression Training 的缩写)包的 Python 版本,具有许多优点。
- 提高工作效率: PyCaret 是一个低代码库,可让你提高工作效率。由于花费更少的时间进行编码,你和你的团队现在可以专注于业务问题。
- 易于使用: 这个简单易用的机器学习库将帮助你以更少的代码行执行端到端的机器学习实验。
- 可用于商业: PyCaret 是一个可用于商业的解决方案。它允许你从选择的 notebook 环境中快速有效地进行原型设计。
你可以在 Python 中创建一个虚拟环境并执行以下命令来安装 PyCaret 完整版:
pip install pycaret [full]
机器学习从业者可以使用 PyCaret 进行分类、回归、聚类、异常检测、自然语言处理、关联规则挖掘和时间序列分析。
使用 PyCaret 构建分类模型
本文通过从 PyCaret 的数据仓库中获取 Iris 数据集来解释使用 PyCaret 构建分类模型。
我们将使用 Google Colab 环境使事情变得简单,并按照下面提到的步骤进行操作。
步骤 1
首先,通过给出以下命令安装 PyCaret:
pip install pycaret
步骤 2
接下来,加载数据集,如图 2 所示:
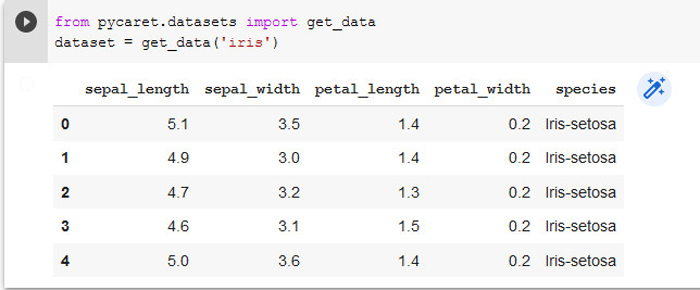
from pycaret.datasets import get_data
dataset = get_data('iris')
(或者)
import pandas as pd
dataset = pd.read_csv('/path_to_data/file.csv')
步骤 3
现在设置 PyCaret 环境,如图 2 所示:
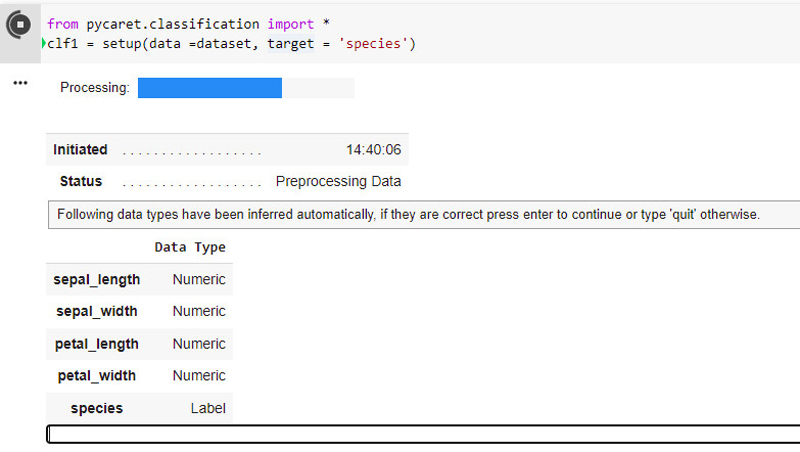
from pycaret.classification import *
clf1 = setup(data=dataset, target = ‘species’)
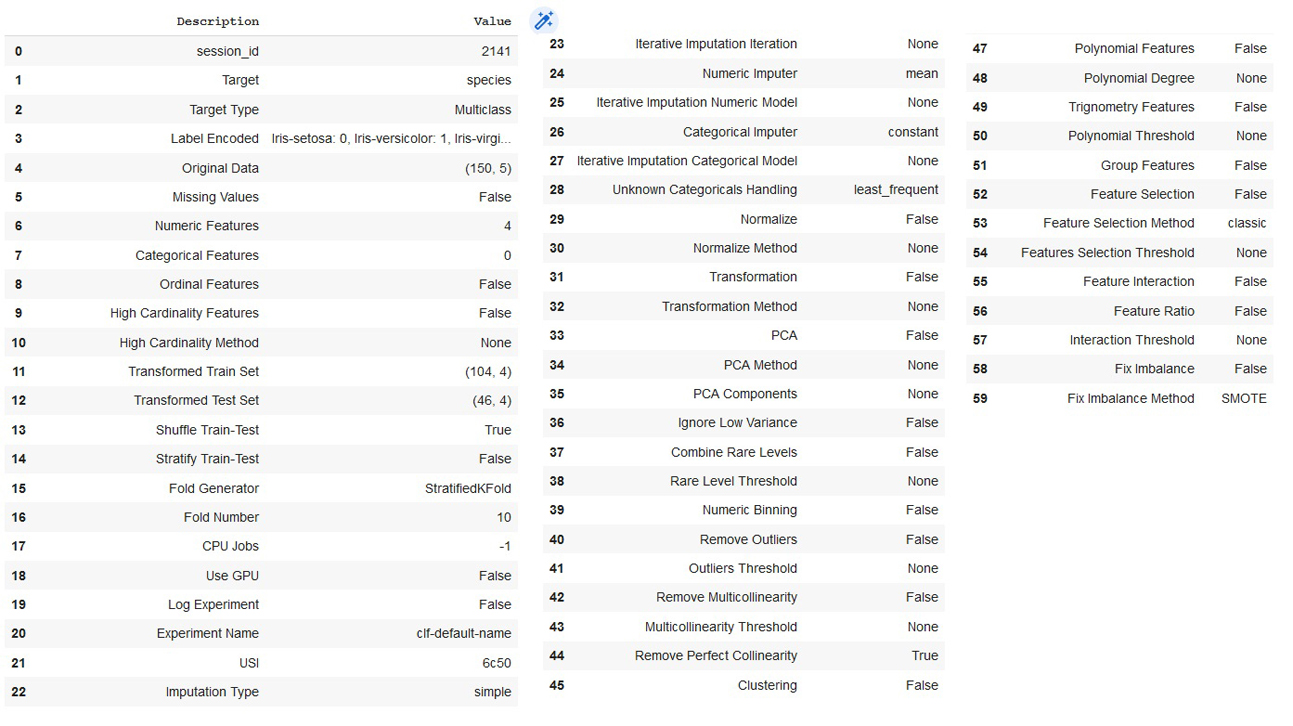
使用 PyCaret 构建任何类型的模型,环境设置是最重要的一步。默认情况下,setup() 函数接受参数 data(Pandas 数据帧)和 target(指向数据集中的类标签变量)。setup() 函数的结果如图 3 所示。 setup() 函数默认将 70% 的数据拆分为训练集,30% 作为测试集,并进行数据预处理,如图 3 所示。
步骤 4
接下来,找到最佳模型,如图 4 所示:
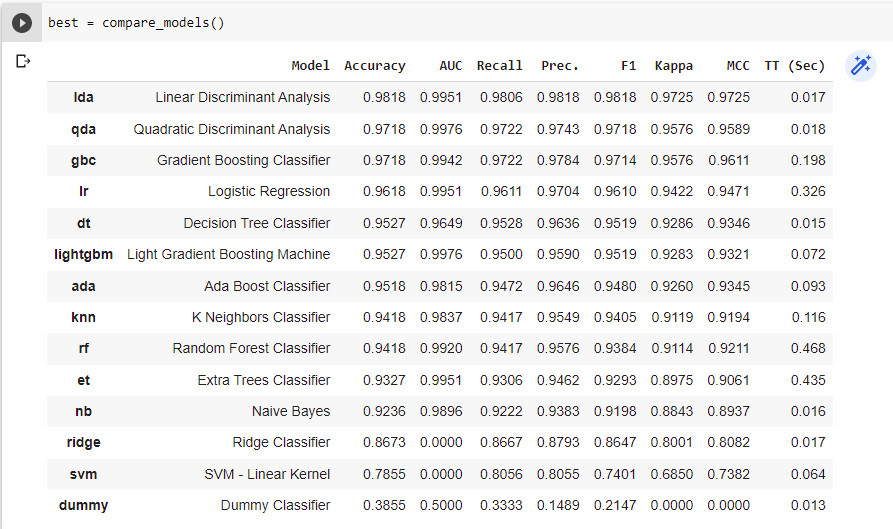
best = compare_models()
默认情况下,compare_models() 应用十倍交叉验证,并针对具有较少训练时间的不同分类器计算不同的性能指标,如准确度、AUC、召回率、精度、F1 分数、Kappa 和 MCC,如图 4 所示。通过将 tubro=True 传递给 compare_models() 函数,我们可以尝试所有分类器。
步骤 5
现在创建模型,如图 5 所示:
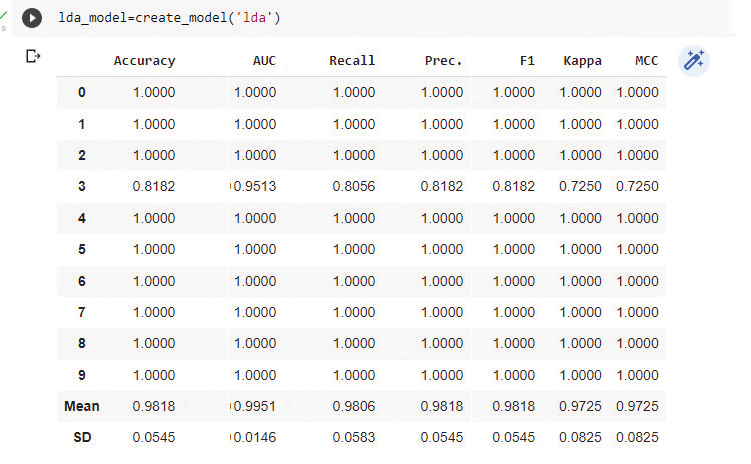
lda_model=create_model (‘lda’)
线性判别分析分类器表现良好,如图 4 所示。因此,通过将 lda 传递给 create_model() 函数,我们可以拟合模型。
步骤 6
下一步是微调模型,如图 6 所示。
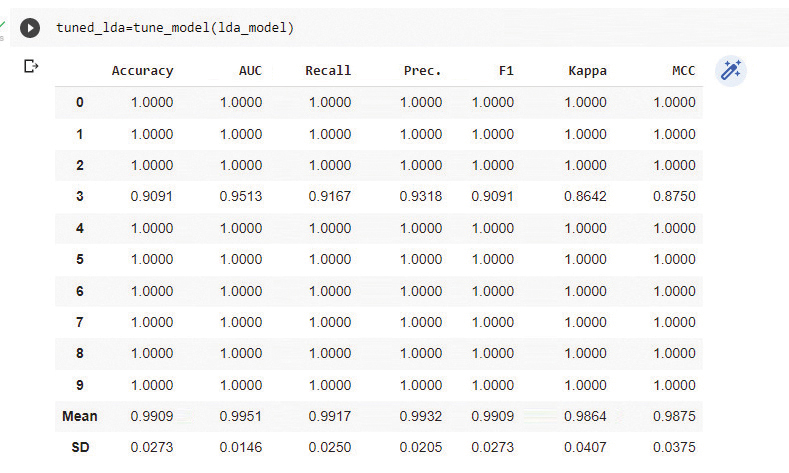
tuned_lda=tune_model(lda_model)
超参数的调整可以提高模型的准确性。tune_model() 函数将线性判别分析模型的精度从 0.9818 提高到 0.9909,如图 7 所示。

步骤 7
下一步是进行预测,如图 8 所示:

predictions=predict_model(tuned_lda)
predict_model() 函数用于对测试数据中存在的样本进行预测。
步骤 8
现在绘制模型性能,如图 9 所示:
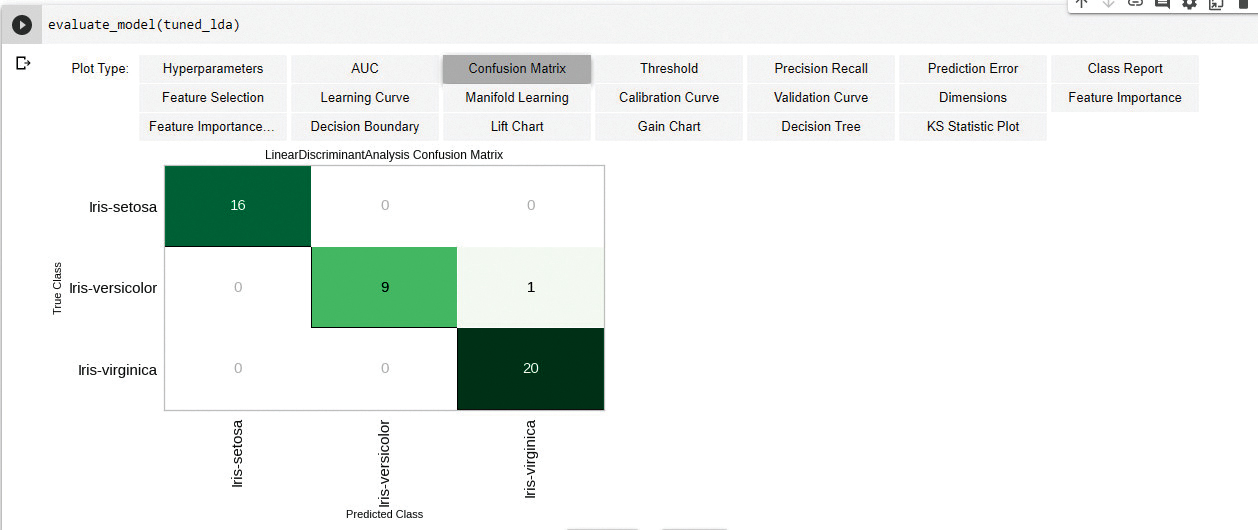
evaluate_model(tuned_lda)
evaluate_model() 函数用于以最小的努力开发不同的性能指标。你可以尝试它们并查看输出。
via: https://www.opensourceforu.com/2022/05/pycaret-machine-learning-model-development-made-easy/
作者:S Ratan Kumar 选题:lkxed 译者:geekpi 校对:wxy