容器环境中的代理模型

我们大多数人都熟悉代理如何工作,但在基于容器的环境中有什么不同?让我们来看看有什么改变。

内联、 侧臂 side-arm 、反向和前向。这些曾经是我们用来描述网络代理架构布局的术语。
如今,容器使用一些相同的术语,但它们正在引入新的东西。这对我是个机会来阐述我最爱的所有主题:代理。
云的主要驱动之一(我们曾经有过成本控制的白日梦)就是可扩展性。在过去五年中,扩展在各种调查中面临着敏捷性的挑战(有时甚至获胜),因为这是机构在云计算环境中部署应用的最大追求。
这在一定程度上是因为在(我们现在运营的)数字经济中,应用已经成为像实体店的“营业/休息”的标牌和导购一样的东西。缓慢、无响应的应用如同商店关灯或缺少营业人员一样。

应用需要随时可用且能够满足需求。扩展是实现这一业务目标的技术响应。云不仅提供了扩展的能力,而且还提供了自动扩展的能力。要做到这一点,需要一个负载均衡器。因为这就是我们扩展应用程序的方式 :使用代理来负载均衡流量/请求。
容器在扩展上与预期没有什么不同。容器必须进行扩展(并自动扩展)这意味着使用负载均衡器(代理)。
如果你使用的是原有的代理机制,那就是采用基于 TCP/UDP 进行基本的负载平衡。一般来说,基于容器的代理的实现在 HTTP 或其他应用层协议中并不流畅,并不能在旧式的负载均衡(POLB)之外提供其他功能。这通常足够了,因为容器扩展是在一个克隆的、假定水平扩展的环境中进行的:要扩展一个应用程序,就添加另一个副本并在其上分发请求。在入口处(在入口控制器和 API 网关中)可以找到第 7 层(HTTP)路由功能,并且可以使用尽可能多(或更多)的应用路由来扩展应用程序。
然而,在某些情况下,这还不够。如果你希望(或需要)更多以应用程序为中心的扩展或插入其他服务的能力,那么你就可以获得更健壮的产品,可提供可编程性或以应用程序为中心的可伸缩性,或者两者兼而有之。
这意味着插入代理。你正在使用的容器编排环境在很大程度上决定了代理的部署模型,无论它是反向代理还是前向代理。更有趣的是,还有第三个模型挎斗模式 ,这是由新兴的服务网格实现支持的可扩展性的基础。
反向代理
反向代理最接近于传统模型,在这种模型中,虚拟服务器接受所有传入请求,并将其分发到资源池(服务器中心、集群)中。
每个“应用程序”有一个代理。任何想要连接到应用程序的客户端都连接到代理,代理然后选择并转发请求到适当的实例。如果绿色应用想要与蓝色应用通信,它会向蓝色代理发送请求,蓝色代理会确定蓝色应用的两个实例中的哪一个应该响应该请求。
在这个模型中,代理只关心它正在管理的应用程序。蓝色代理不关心与橙色代理关联的实例,反之亦然。
前向代理

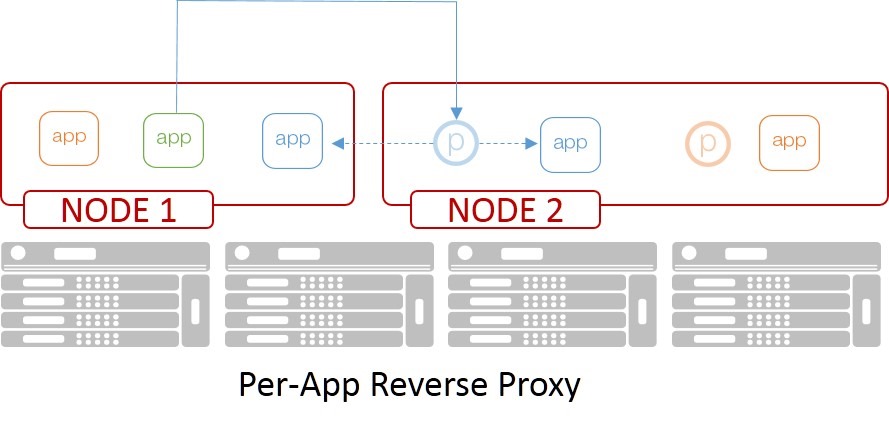
这种模式更接近传统的出站防火墙的模式。
在这个模型中,每个容器 节点 都有一个关联的代理。如果客户端想要连接到特定的应用程序或服务,它将连接到正在运行的客户端所在的容器节点的本地代理。代理然后选择一个适当的应用实例,并转发客户端的请求。
橙色和蓝色的应用连接到与其节点相关的同一个代理。代理然后确定所请求的应用实例的哪个实例应该响应。
在这个模型中,每个代理必须知道每个应用,以确保它可以将请求转发给适当的实例。
挎斗代理

这种模型也被称为服务网格路由。在这个模型中,每个容器都有自己的代理。
如果客户想要连接到一个应用,它将连接到挎斗代理,它会选择一个合适的应用程序实例并转发客户端的请求。此行为与前向代理模型相同。
挎斗代理和前向代理之间的区别在于,挎斗代理不需要修改容器编排环境。例如,为了插入一个前向代理到 k8s,你需要代理和一个 kube-proxy 的替代。挎斗代理不需要这种修改,因为应用会自动连接到 “挎斗” 代理而不是通过代理路由。
总结
每种模式都有其优点和缺点。三者共同依赖环境数据(远程监控和配置变化),以及融入生态系统的需求。有些模型是根据你选择的环境预先确定的,因此需要仔细考虑将来的需求(服务插入、安全性、网络复杂性)在建立模型之前需要进行评估。
在容器及其在企业中的发展方面,我们还处于早期阶段。随着它们继续延伸到生产环境中,了解容器化环境发布的应用程序的需求以及它们在代理模型实现上的差异是非常重要的。
这篇文章是匆匆写就的。现在就这么多。
via: https://dzone.com/articles/proxy-models-in-container-environments
作者:Lori MacVittie 译者:geekpi 校对:wxy