
作为一位 Linux 管理员,你需要跟踪所有用户的活动。

使用 Python 制作一个 API 来监控你的树莓派硬件,并使用 Appsmith 建立一个仪表盘。

使用这个方便的应用查看你的网络连接。

我希望网站大部分时间都能正常工作,但我也希望不用在持续的运营上花费时间。

Zeek 是一个开源的网络安全监控工具。本文讨论了如何将 Zeek 与 ELK 集成。

“系统监控中心”是一个多合一的开源应用,不用使用多种工具就可以监控基本的系统资源情况。

一个用于现代 Linux 系统的 Apache 2.0 许可的资源监视器。below 可以让你重放以前记录的数据。

如何找到一个程序的进程 ID(PID)。最常见的 Linux 工具是由 procps-ng 包提供的,包括 ps、pstree、pidof 和 pgrep 命令。

使用微控制器、传感器、Python 以及 MQTT 持续追踪温室的温度、湿度以及环境光。

这篇文章是一篇关于 Prometheus 中的时间序列数据库的设计思考,虽然写作时间有点久了,但是其中的考虑和思路非常值得参考。

这个开源解决方案可以简单而有效地监控你的云基础设施。
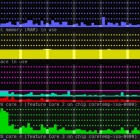
所有这些只允许我们监控系统利用率而不能监控系统硬件。但是 Hegemon 允许我们在单个仪表板中监控两者。

watch、top 和 ac 命令为我们监视 Linux 服务器上的活动提供了一些十分高效的途径。

使用 WTF 将关键信息置于视野之中,这个系列中第六个开源工具可使你在 2019 年更有工作效率。
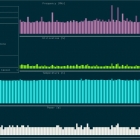
它其实是一个压力测试的终端 UI,可以帮助管理员通过颜色查看 CPU 温度。
在本文中,我将使用 Graylog (用于日志)和 Prometheus (用于指标)去打造一个 Kubernetes 集群的监视解决方案。

ctop 为多个容器提供了一个简洁凝练的实时指标概览。它是一个类 top 的针对容器指标的界面。

您需要监控 Linux 服务器的性能吗?试试用这些内置命令和附加工具吧!大多数 Linux 发行版都附带了大量的监控工具。这些工具提供了获取系统活动的相关指标。您可以使用这些工具来查找性能问题的可能原因。
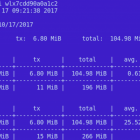
通过 iftop、 nethogs 和 vnstat 详细了解你的网络连接状态。

一个获得关于慢查询、意外错误和其它重要日志通知的简单 Go 秘诀。

Zabbix 是企业级开源分布式监控服务器解决方案。该软件能监控网络的不同参数以及服务器的完整性,还允许为任何事件配置基于电子邮件的警报。Zabbix 根据存储在数据库(例如 MySQL)中的数据提供报告和数据可视化功能。软件收集的每个测量指标都可以通过基于 Web 的界面访问。

ps_mem 是一个可以帮助我们精确获取 Linux 中各个程序核心内存使用情况的简单 python 脚本。这个工具和其它的区别在于其精确显示核心内存使用情况。

ttyload 是一个轻量级的实用程序,它为 Linux 和其他类 Unix 系统上提供随着时间变化的彩色平均负载。它使用标准的硬编码 ANSI 转义序列进行屏幕显示和着色。

Linfo 是可扩展的,通过 composer,很容易使用 PHP5 库以程序化方式获取来自 PHP 应用的丰富的系统统计数据。它有 Web UI 及其Ncurses CLI 视图,在 Linux、Windows、BSD、Darwin/Mac OSX、Solaris 和 Minix 系统上均可用。

cpustat 是 Linux 下一个强大的系统性能测量程序,它用 Go 编程语言 编写。它通过使用 “用于分析任意系统的性能的方法(USE)”,以有效的方式显示 CPU 利用率和饱和度。

pyDash 是一个轻量且基于 web 的 Linux 性能监测工具,它是用 Python 和 Django 加上 Chart.js 来写的。经测试,在下面这些主流 Linux 发行版上可运行:CentOS、Fedora、Ubuntu、Debian、Raspbian 以及 Pidora 。

bmon 是类 Unix 系统中一个基于文本,简单但非常强大的 网络监视和调试工具,它能抓取网络相关统计信息并把它们以用户友好的格式展现出来。它是一个可靠高效的带宽监视和网速估测工具。

它的核心建立在内核模块上,用于从每个 CPU 核心检索内部性能计数器,并且与收集数据的守护进程一起工作,一个小型控制台客户端连接到该守护程序并显示收集的数据。

最常见的云优化的行为中,45% 的大公司和中小型企业关注的是监控。

它用 Go 语言编写,不需要在要监视的服务器上安装任何额外的程序,除了 SSH 服务器和登录凭据。
本文将向你介绍 Ganglia,它是一个易于扩展的监控系统。使用它可以实时查看 Linux 服务器和集群(图形化展示)中的各项性能指标。

- 监控容器及其里面的东西。
- 在服务性能上做监控,而不是容器性能。
- 监控弹性和多地部署的服务。
- 监控 API。
- 将您的监控映射到您的组织结构。

Grafana 是一个有着丰富指标的开源控制面板。在可视化大规模测量数据的时候是非常有用的。根据不同的指标数据,它提供了一个强大、优雅的来创建、分享和浏览数据的方式。
如果你正在运行 Swarm 模式的集群,或者只运行单台 Docker,你都会有下面的疑问:我如何才能监控到它们都在干些什么?

Shinken 是一个用 Python 实现的开源的主机和网络监控框架,并与 Nagios like 兼容,它可以运行在所有支持 Python 程序的操作系统上,比如说 Linux、Unix 和 Windows。
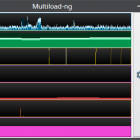
Multiload-ng 是一个 GTK2 图形化系统监视器应用,可集成到 Xfce、LXDE 及 MATE 的桌面面板中, 它 fork 自原来的 GNOME Multiload 应用。它也可以运行在一个独立的窗口中。

和其它传统的内存报告工具不同的是,它有个独特的功能,可以报告 PSS(按比例占用大小 Proportional Set Size),这种内存使用量表示方法对于那些在虚拟内存中的应用和库更有意义。

Netdata 是一个实时的资源监控工具,它拥有基于 web 的友好界面。它很像 Nagios 等别的监控软件;但是,Netdata 仅仅支持通过 Web 界面进行实时监控。
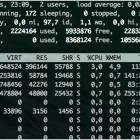
随着互联网行业的不断发展,各种监控工具多得不可胜数。这里列出网上最全的监控工具。让你可以拥有超过80种方式来管理你的机器。

Munin 是一款类似 RRD tool 的非常棒的系统监控工具,它能提供给你多方面的系统性能信息,例如 磁盘、网络、进程、系统和用户。这些是 Munin 默认监控的内容。 Munin 如何工作? Munin 以客户端-服务器模式运行。主服务器上运行的 Munin 服务器进程会从本地运行的客户端守护进程(Munin 可以监控它自己的资源)或者远程客户端(Munin 可以监控上百台机器)收集数据,然后在它的 web 界面上以图形的方式显示出来。 在服务器中配置 Munin 要配置服务器端和客户端,我们需要完成以下两步。 安装 Munin 服务器软件包并配置,使得它能从客户端
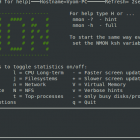
Nmon(得名于 Nigel 的监控器)是IBM的员工 Nigel Griffiths 为 AIX 和 Linux 系统开发的一款计算机性能系统监控工具。Nmon 可以把操作系统的统计数据展示在屏幕上或者存储到一份数据文件里,来帮助了解计算机资源的使用情况、调整方向和系统瓶颈。这个系统基准测试工具只需要使用一条命令就能得到大量重要的性能数据。使用 Nmon 可以很轻松的监控系统的 CPU、内存、网络、硬盘、文件系统、NFS、高耗进程、资源和 IBM Power 系统的微分区的信息。 Nmon 安装 Nmon 默认是存在于 Ubuntu 的仓库中的。你可以通过下面的命令安装 Nmon: sudo a
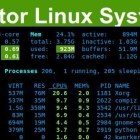
Glances 是一个用于监控系统的跨平台、基于文本模式的命令行工具。它是用 Python 编写的,使用 psutil 库从系统获取信息。你可以用它来监控 CPU、平均负载、内存、网络接口、磁盘 I/O,文件系统空间利用率、挂载的设备、所有活动进程以及消耗资源最多的进程。Glances 有很多有趣的选项。它的主要特性之一是可以在配置文件中设置阀值(careful(小心)、warning(警告)、critical(致命)),然后它会用不同颜色显示信息以表明系统的瓶颈。 Glances 的功能 CPU 平均负载 不同状态(如活动、休眠)进程的数量 所有内存信息,如物理内存、

如果你已经阅读了前面的如何监控 NGINX,你应该知道从你网络环境的几个指标中可以获取多少信息。而且你也看到了从 NGINX 特定的基础中收集指标是多么容易的。但要实现全面,持续的监控 NGINX,你需要一个强大的监控系统来存储并将指标可视化,当异常发生时能提醒你。在这篇文章中,我们将向你展示如何使用 Datadog 安装 NGINX 监控,以便你可以在定制的仪表盘中查看这些指标: Datadog 允许你以单个主机、服务、流程和度量来构建图形和警告,或者使用它们的几乎任何组合构建。例如,你可以监控你的所有主机,或者某个特定可用区域的所有N

Darkstat是一个简易的,基于网页的流量分析程序。它可以在主流的操作系统如Linux、Solaris、MAC、AIX上工作。它以守护进程的形式持续工作在后台,不断地嗅探网络数据,以简单易懂的形式展现在它的网页上。它可以为主机生成流量报告,识别特定的主机上哪些端口是打开的,它兼容IPv6。让我们看下如何在Linux中安装和配置它。 在Linux中安装配置Darkstat 在Fedora/CentOS/RHEL中安装Darkstat: 要在Fedora/RHEL和CentOS中安装,运行下面的命令。 sudo yum install darkstat 在Ubuntu/Debian中安装Darkstat: 运行下面的命令在Ubuntu和Debia

NGINX 是什么? NGINX (发音为 engine X) 是一种流行的 HTTP 和反向代理服务器。作为一个 HTTP 服务器,NGINX 可以使用较少的内存非常高效可靠地提供静态内容。作为反向代理,它可以用作多个后端服务器或类似缓存和负载平衡这样的其它应用的单一访问控制点。NGINX 是一个自由开源的产品,并有一个具备更全的功能的叫做 NGINX Plus 的商业版。 NGINX 也可以用作邮件代理和通用的 TCP 代理,但本文并不直接讨论 NGINX 的那些用例的监控。 NGINX 主要指标 通过监控 NGINX 可以 捕获到两类问题:NGINX 本身的资源问题,和出现在你的基础网络设

Nagios内置了很多脚本来监控服务。本篇会使用其中一些来检查通用服务如MySql、Apache、DNS等等。 为了保证本篇集中在系统监控,我们不会在这里配置主机组或者模板,它们已经在 前面的教程中覆盖了,它们可以满足需要了。 在命令行中运行Nagios 通常建议在添加到Nagios前,先在命令行中运行Nagios服务检测脚本。它会给出执行是否成功以及脚本的输出将会看上去的样子。 这些脚本存储在 /etc/nagios-plugins/config/ ,可执行文件在 /usr/lib/nagios/plugins/。 下面就是该怎么做 root@nagios:~# cd /etc/nagios-plugins/config/ 提供的脚

当今世界,人们的计算机都相互连接,互联互通。小到你的家庭局域网(LAN),大到最大的一个被我们称为互联网。当你管理一台联网的计算机时,你就是在管理最关键的组件之一。由于大多数开发出的应用程序都基于网络,网络就连接起了这些关键点。 这就是为什么我们需要网络监控工具。ntop 是最好的网络监控工具之一。来自维基百科的知识ntop是一个网络探测器,它以与top显示进程般类似的方式显示网络使用率。在交互模式中,它显示了用户终端上的网络状态。在网页模式中,它作为网络服务器,创建网络状态的HTML转储文件。它支持NetFlow/sFlowe
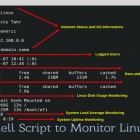
系统管理员的任务真的很艰难,因为他/她必须监控服务器、用户、日志,还得创建备份,等等等等。对于大多数重复性的任务,大多数管理员都会写一个自动化脚本来日复一日地重复这些任务。这里,我们已经写了一个shell脚本给大家,用来自动化完成系统管理员所要完成的常规任务,这可能在多数情况下,尤其是对于新手而言十分有用,他们能通过该脚本获取到大多数的他们想要的信息,包括系统、网络、用户、负载、内存、主机、内部IP、外部IP、开机时间等。 我们已经注意并进行了格式化输出(在一定程度上哦)。此脚本不包含任何恶意内容,并且它

很多Linux系统管理员依赖一个集中式的远程监控系统(比如Nagios或者Cacti)来检查他们网络基础设备的健康状况。虽然集中式监控让管理员的生活更简单了,然而处理很多机器和服务时,专用的监控中心显然成为了一个单点故障,如果监控中心挂了或者因为什么原因(比如硬件或者网络故障)不可访问了,你就会失去整个网络基础设备情况的任何信息。 一个给你的监控系统增加冗余度的方法是安装独立的监控软件(作为后备),至少在网络中的关键/核心服务器上。这样在集中式监控系统挂掉的情况,你还有能力通过后备的监控方式来获取核心服务器的运行
简介 在监控你的服务器、交换机或者设备时遇到过问题吗?Observium 可以满足你的需求。这是一个免费的监控系统,它可以帮助你远程监控你的服务器。它是一个由PHP编写的基于自动发现 SNMP 的网络监控平台,支持非常广泛的网络硬件和操作系统,包括 Cisco、Windows、Linux、HP、NetApp 等等。在此我会给出在 Ubuntu 12.04 上一步步地设置一个 Observium 服务器的介绍。 目前有两种不同的 observium 版本。 Observium 社区版本是一个在 QPL 开源许可证下的免费工具,这个版本是对于较小部署的最好解决方案。该版本每6个月进行一次安全性更